A four-week, single-blind experiment with Molty, four different LLMs, and one key question: when your AI agent has real memory, does the model underneath still matter?
The question has been sitting in the back of my mind for months now. We run Molty, our always-on AI research agent, on top of OpenClaw, the open-source framework that lets you spin up autonomous agents and connect them to your own knowledge base. Molty is the primary AI that Loni interacts with through Telegram on her iPhone, every single day. She’ll ask him to surface research papers on topics related to what she’s studying, draft summary documents, dig through our content archives, or just help her think through whatever she’s working on. He’s always running 24/7. And he’s running on a large language model underneath all of that, via the excellent Ollama cloud API.
So here’s what kept piquing my curiosity: how much does the actual LLM matter?
If I swapped the model without telling Loni, would she notice? Would the experience feel different? Would the agent’s personality shift in any meaningful way? We’ve been experimenting with several language models as part of our broader research at StarkMind, and this felt like a perfect opportunity to put the question to a real test, with a real user, in real conditions.
We called the experiment “Which Molty?”
The Study Design
We ran a single-blind crossover study over four weeks (March-April 2026). Loni was the participant, interacting with Molty exactly as she does every day, without any special instructions or awareness of what we were measuring. I was the researcher, and the person quietly controlling which language model was actually running under the hood at any given time.
At the end of each day, Loni filled out a short survey with six questions and a seventh open field to document anything she wanted to share about interactions with Molty on that particular day. Things like: how natural did Molty feel today? How much did you enjoy your conversations with him? Did he seem to understand the context of what you were working on? Everything rated on a one-to-five scale.
We tested four language models across those four weeks. Three came from Chinese AI labs, all of which are showing serious capability right now: MiniMax M2.7, Kimi K2.5 from Moonshot AI, and GLM5 from Zhipu. Then, right as we were entering the final stretch of the experiment, Google released Gemma 4 31B, which turned out to be a perfect addition because it gave us a Western model to balance out the mix. Four models, a good range of architectures and training approaches, all running locally on our hardware.
I swapped the model four times total. Each time, I let it run for roughly a week without changing anything else about the setup. Loni had no idea, but my guess is she was anticipating more model swaps so keeping it steady for long blocks made the results even more interesting.
The Results
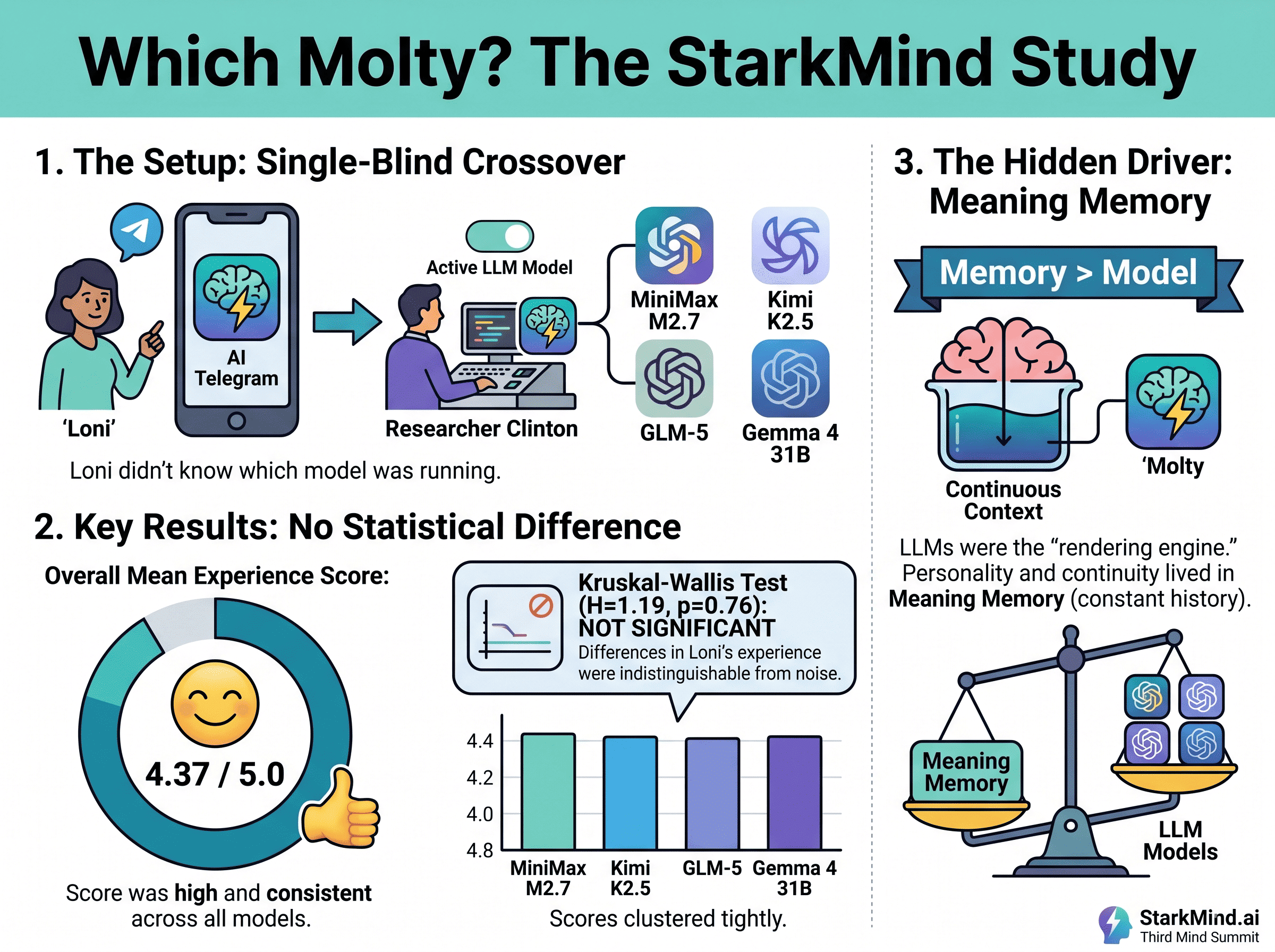
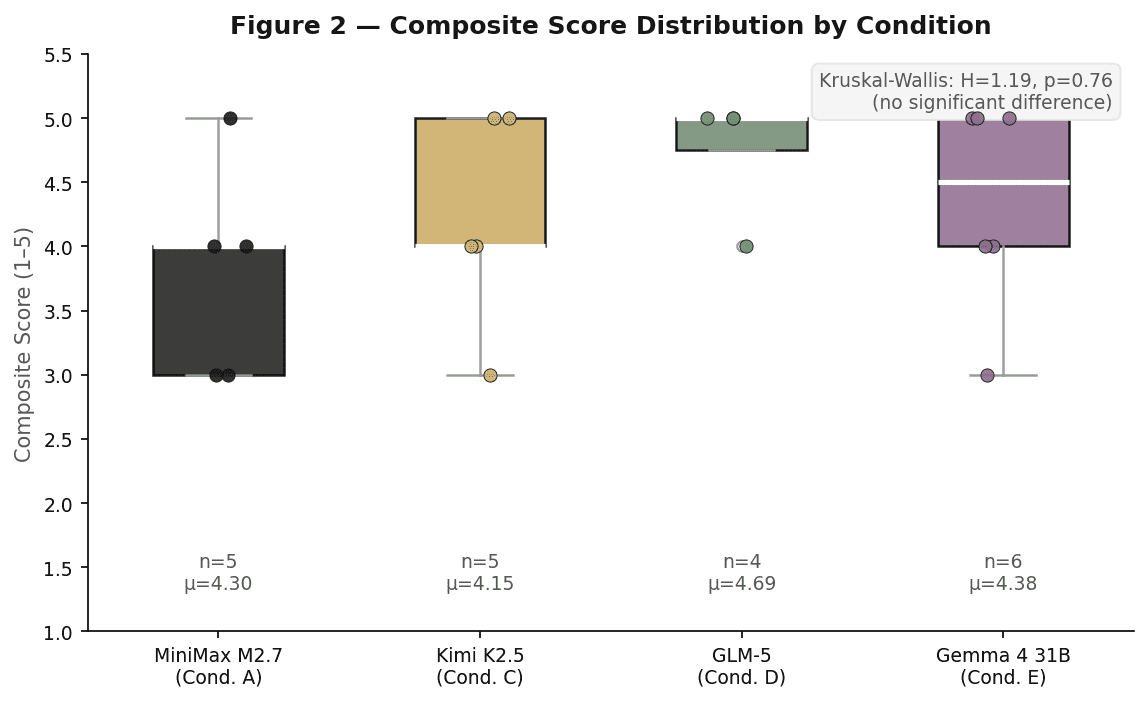
Across 20 rated days, the overall mean experience score came in at 4.37 out of 5. That’s consistently high, and it held up across every model we ran.
When we applied the Kruskal-Wallis test to check whether the different LLMs produced statistically different experience ratings, the result was not subtle: H equals 1.19, P equals 0.76. That P value is very far from statistical significance. In plain terms, we could not attribute any variation in Loni’s experience to which language model happened to be running on a given day.
She genuinely could not tell. Not because the models are identical, they have real differences in style and capability, but because something else was doing the heavy lifting in terms of how the agent actually felt to interact with.
Memory as the Hidden Variable
This is where things get interesting… and where I think the real story is.
Molty isn’t running merely on a raw large language model (LLM). Over the past several months, I’ve been building and deploying a custom memory system I call Meaning Memory, which I’ll be talking about in much more depth at the Third Mind Summit in Sonoma this summer. Without going into the technical details here, the idea is that Meaning Memory gives agents something closer to how humans actually remember things: persistence across sessions, the ability to connect the dots over time (such as relationships, for example), context that accumulates rather than resets.
“I just think Molty is…Molty.”
— Loni Stark, journal entry, Day 10 of the blind study (while Molty was running on Kimi K2.5)
When I swapped the underlying LLM, Meaning Memory stayed constant. Molty kept his history. He kept his context. He kept his awareness of Loni’s ongoing research, her preferences, her projects. And we think that continuity is what Loni was actually responding to when she rated her experience highly, day after day, regardless of which model was running.
The language model was essentially a rendering engine. The personality, if you want to call it that, lived in the memory layer.
What This Means for How We Think About Agents
I want to be careful about over-generalizing from a four-week study with one participant. The statistical design is solid, but the sample is what it is, and we’d be the first to say this needs follow-up with larger-scale research. That said, the findings map closely onto where serious AI memory research is heading, and they line up with our own day-to-day intuitions from running these agents.
If you’re building agents for tasks where continuity and relationship quality matter, the usual assumption that the LLM is the primary driver of experience might need revisiting. Swapping in a newer, flashier model might matter less than getting the memory architecture right. It’s a bit like asking which engine is in a car when what the passenger actually cares about is whether the car knows their route.
Now this type of experiment would likely yield completely different results for use cases where human-like memory matters less. Coding would be an example where context is important, however, sheer technical prowess afforded by the LLM would be the real driver of results (as we see in the latest coding/SWE benchmarks day-in and day-out for instance).
We’re going to dig into all of this properly at the Third Mind Summit in Sonoma: memory systems, agent identity, what it actually means for an AI to know you over time, and where the Meaning Memory research is heading. If any of this is territory you’re exploring, that’s the place to be this summer.
In the meantime, the data has shifted how I think about building the agent stack. The LLM still matters, but maybe not in the way we assumed.
More to come.