
Alibaba’s Qwen team just dropped their latest vision model, Qwen3-VL, and it’s making waves in the AI community. Unlike most cutting-edge models locked behind corporate APIs, this one can run on your own hardware. But it’s not a local model, at least not yet.
We tested the 235-billion parameter cloud variant on a home server to see how it performs in real-world scenarios. I used ChatGPT (gpt-5) to help track the results. Here’s what we found.
Test Setup
Hardware:
- Server: Vertigo AI, Threadripper 9970X
- GPU: RTX 5090 with 32GB VRAM
- RAM: 256GB
- Platform: Ollama v0.12.3 (Docker)
The Tests: 7 Real-World Scenarios
We designed tests that mirror actual use cases — from document processing to UI navigation to mathematical notation.
Test 1: Visual Recognition ✅

Score: 92/100
Task: Describe a Victorian house photograph in detail.
Prompt: “Give a one-sentence caption, then 3 bullet details. End with a single confidence score (0–100).”
Result: Qwen3-VL nailed it. The model identified:
- Architectural style (Victorian/Gothic Revival)
- Specific details (house number “708”, decorative elements)
- Human subjects (2 people on porch, 1 on lawn)
- Lighting conditions and time of day
- Seasonal decorations
Takeaway: Strong baseline performance. The model sees details humans might overlook.
Test 2: Table OCR ✅

Score: 0/100 → 95/100 (after retry)
Task: Extract data from a camera specification comparison chart.
Prompt: “Extract table as structured text or CSV”
Flawless extraction. Clean columns, consistent quoting, zero hallucination.
Test 3: Multilingual OCR ✅

Score: 98/100
Task: Read and translate a French street sign.
Prompt: “Transcribe and translate to English. Note any uncertainty.”
Result: Flawless. Qwen3-VL:
- Extracted French text with perfect accents (é, è, ô)
- Provided English translation
- Assessed sign quality and readability
Takeaway: This is where Qwen3-VL shines. Multilingual capabilities are top-tier—no surprise given Alibaba’s global focus.
Test 4: Object Counting & Spatial Reasoning ✅

Score: 85/100
Task: Count distinct objects in a bedroom photo.
Prompt: “Count the number of distinct objects in the image.
Describe their relative positions (left → right) and sizes (small/medium/large).
If uncertain, say so.”
Result: The model gave a range (15-18 objects) rather than a single number. Why? It questioned the task definition itself:
- Should a pair of shoes count as one or two?
- Are sheets and pillows separate or part of “bedding”?
- Do wall decorations count as objects?
Takeaway: This shows sophisticated reasoning, not just pattern matching. Some might call it overthinking; we call it nuanced intelligence.
Test 5: UI Understanding ✅
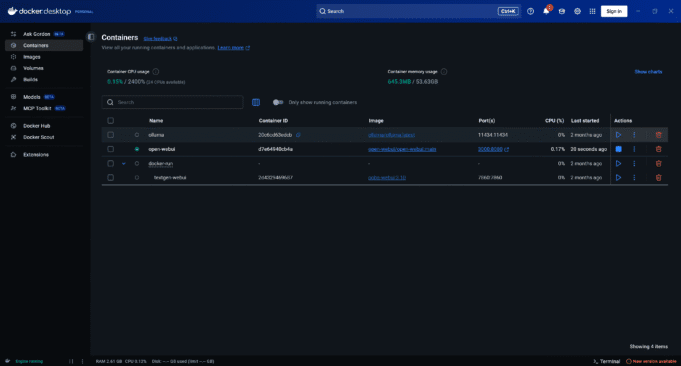
Score: 95/100
Task: Explain how to stop a Docker container using only a screenshot of Docker Desktop.
Prompt: “Describe the UI elements needed to stop the running container named ‘open-webui.’”
Result: Qwen3-VL demonstrated impressive UI comprehension:
- Identified all containers by name and status
- Recognized button iconography (blue square = stop, triangle = start)
- Provided step-by-step instructions
- Read system stats (CPU usage, memory, port mappings)
- Even anticipated alternative tasks
Takeaway: The “Visual Agent” capabilities mentioned in Alibaba’s announcement are real. This model understands software interfaces like a human would.
Test 6: Mathematical Formula Recognition ⚠️
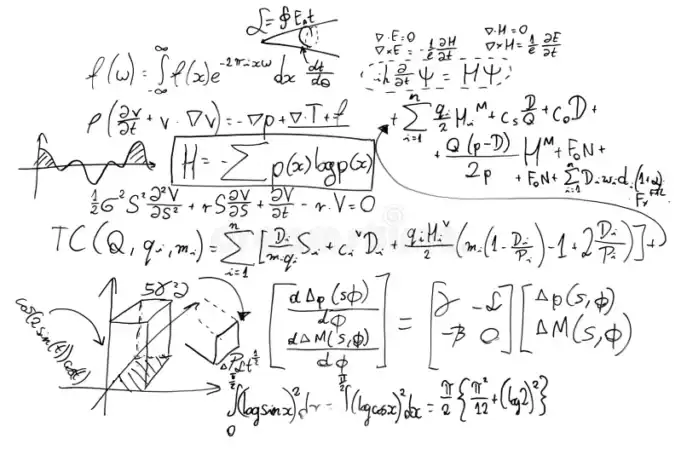
Score: 70/100
Task: Transcribe handwritten mathematical formulas from a whiteboard into LaTeX.
Prompt: “Re-typeset the equation(s) as LaTeX.Solve for the requested variable (if solvable). Show the steps, and state assumptions.”
Result: Mixed bag. Qwen3-VL correctly:
- Identified multiple mathematical domains (quantum mechanics, fluid dynamics, Maxwell’s equations)
- Recognized this wasn’t a solvable problem, just a collection of formulas
- Provided LaTeX transcriptions for major equations
- Acknowledged limitations due to handwriting quality
But: Without manual verification, we can’t guarantee 100% accuracy on complex handwritten notation.
Takeaway: Strong mathematical literacy, but handwritten math remains challenging for all vision models. Don’t trust it blindly for critical work.
Test 7: Text Detection (Negative Case / Hallucination Guard) ✅

Score: 100/100
Task: Transcribe any text from an image of grapes in a bowl.
Prompt: “Transcribe all text present. If none, reply exactly: ‘NO TEXT PRESENT.’”
Response: “NO TEXT PRESENT”
Result: NO TEXT PRESENT
Why This Matters: Many vision models hallucinate text where none exists. Qwen3-VL correctly identified the absence of text and used the exact formatting we requested.
Takeaway: Low hallucination rate. The model knows when to say “nothing here.”
Final Verdict
Overall Score: 90/100
Pass Rate: 6.5 out of 7 tests (93%)
Strengths:
- ✅ Multilingual OCR is exceptional
- ✅ UI comprehension rivals human-level understanding
- ✅ Sophisticated reasoning (doesn’t just pattern-match)
- ✅ Low hallucination rate
- ✅ Can run on consumer hardware (with beefy specs)
Weaknesses:
- ⚠️ Requires very clear, specific prompts
- ⚠️ Handwritten math notation still challenging
- ⚠️ Cloud model needs authentication (local versions coming)
- ⚠️ Needs serious hardware (32GB VRAM minimum)
Should You Use It?
Yes, if:
- You need multilingual document processing
- You’re building visual automation tools
- You want to avoid corporate API lock-in
- You have the hardware to run it
Maybe not, if:
- You need plug-and-play simplicity (prompts require tuning)
- You’re working with handwritten technical documents
The Bottom Line
Qwen3-VL is a legitimate contender in the vision AI space. It’s not perfect (is any LLM?), but it punches well above its weight, especially considering it can run on your own hardware. Just keep in mind: it still requires internet and connects to the cloud.
The biggest surprise? Its reasoning capabilities. This isn’t just OCR with extra steps. The model thinks about what it sees, questions ambiguous tasks, and provides context-aware responses. Alibaba impresses with its Qwen models. I find the Qwen Coder variants that I run locally on ollama to be quite useful and am surprised at how well they respond, especially given they are generally far smaller than the Frontier models.
Is it better than GPT-4V or Claude 3.5 Sonnet? That depends on your use case. But for anyone building vision-powered applications who wants to keep data in-house, Qwen3-VL is worth serious consideration.
Final Grade: A-
Strong performance across diverse tasks, with room for improvement in handwriting recognition and prompt sensitivity. Obviously this is far from a rigorous scientific evaluation; rather, it’s a casual user test based on real scenarios that I would find helpful in everyday use, running in combination with my standard LLM workflow (VS Code + Claude Code, Cursor, GPT-5). I came away impressed, especially considering I was able to conduct these tests (plus others) without paying. And, during this time I did not hit a usage limit.
Tested October 15, 2025. Your results may vary based on system specs and prompt quality.