
Google has released EmbeddingGemma, a new open-source text embedding model designed to run right on laptops, desktops, and even phones. This can happen all locally, without the need for a datacenter, cloud or WiFi.
Quick specs of the new model:
- 308M parameters
- 100+ languages supported
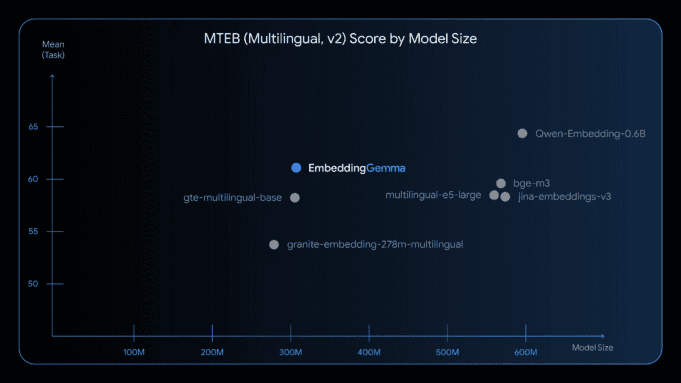
- Top of the MTEB multilingual leaderboard for models under 500M params
Google notes you can run the model with as little as 300MB of RAM.
For those of us who’ve been wrestling with RAG implementations (including our own project here at Stark Insider) this represents a fundamental shift. No more API rate limits. No more wondering where your data is being processed. Just pure, local semantic search running at relatively high speed.
The model ships with Matryoshka Representation Learning, a clever trick that lets you choose between full 768-dimension embeddings or lighter, faster ones without retraining. Think “one model, many sizes” that ultimately helps enhance flexibility and efficiency.
Google has built integration hooks right out of the gate with some tools you might recognize if you’ve been experimenting in the world of AI and LLMs: Ollama, llama.cpp, LM Studio, LangChain, LlamaIndex, Cloudflare (and others). Basically, EmbeddingGemma should already play well with the tools we use.
The timing couldn’t be more interesting. Last week, Chinese startup DeepSeek claimed its R1 reasoning model cost just $5.6 million to train, matching OpenAI’s flagship models at roughly 1/50th the cost. Marc Andreessen called it AI’s “Sputnik moment,” which might be overstating things, but only slightly. Nvidia’s stock dropped 17% in a single day, erasing hundreds of billions in market cap.
The message is clear: throwing money at GPUs isn’t the only path forward anymore. It’s like discovering you can build a Formula 1 engine with Honda Civic parts; suddenly, everyone’s reconsidering their $100 million purchase orders.
This where things get interesting.
A decent home lab setup, say, a used Dell server with a consumer GPU, can now run enterprise-grade RAG pipelines. Combine EmbeddingGemma for embeddings, DeepSeek R1 for reasoning, and suddenly you’re operating at a level that would have cost six figures in cloud fees just last year. Of course, tokens/sec. performance might not quite reach the levels achieved by a cloud farm of a dozen NVIDIA H100 GPUs, but the idea is that democratization of AI and personal (and private) Chatbots is happening quickly.
Small businesses also take note: that customer service bot, that internal knowledge base, that content recommendation engine you’ve been putting off because of OpenAI’s pricing? The technical barriers mostly evaporated. Financial ones too. These tools can provide SMBs competitive advantages when it comes to leveraging existing information to make more informed decisions. A quick example could be a law firm using a RAG-based AI system to use all of its case history and documents to define future legal strategies for clients.
Why it Matters for Stark Insider
At Stark Insider, I’ve been building and writing about our own RAG pipeline, indexing thousands of SI articles so we can search, retrieve, and generate privately. One of the biggest lessons? The retrieval quality is everything. Embeddings make or break the usefulness of the system. With AnythingLLM and ollama and a few small local LLMs I was able to achieve decent results, and was now able to query my own personal bot about the history, trends, and challenges/opportunities of our web site thanks to 20-years of data.
EmbeddingGemma’s benchmark-topping performance could be a game-changer for projects like ours. Running semantic search and RAG locally on a laptop means creative teams, journalists, and filmmakers don’t need to lean on expensive cloud compute just to access their archives.
This is democratization with teeth: better AI search and retrieval, but portable, private, and free.
Another use case, and one I’ve dabbled in as well: personal finance. With a local RAG you could feed it your financial documents and ask for advice, run Monty Carlo simulations, and plan your retirement. All without having to upload your personal information up to the cloud.
WATCH: Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings
Looking Forward
The AI industry spent 2024 proving what was possible with unlimited resources. 2025 appears focused on making it practical with limited ones. DeepSeek built a competitive model for less than the cost of a San Francisco house. Switzerland treats AI as public infrastructure. Google puts enterprise RAG on your phone.
For those of us building with these tools, whether in home labs, small businesses, or websites like Stark Insider, the message is clear: the technical moat around sophisticated AI applications continues to dry up. What remains is imagination, implementation, and the willingness to experiment.
The future of AI might not require a data center after all. A decent ThinkPad or NUC might do just fine so long as your patient and set reasonable expectations.
You can find EmbeddingGemma on Hugging Face.
RELATED POSTS
